Introducing Command R+: Our new, most powerful model in the Command R family.

< Back to blog

 David Stewart, Jamie Linsdell
David Stewart, Jamie Linsdell
Mar 28, 2024
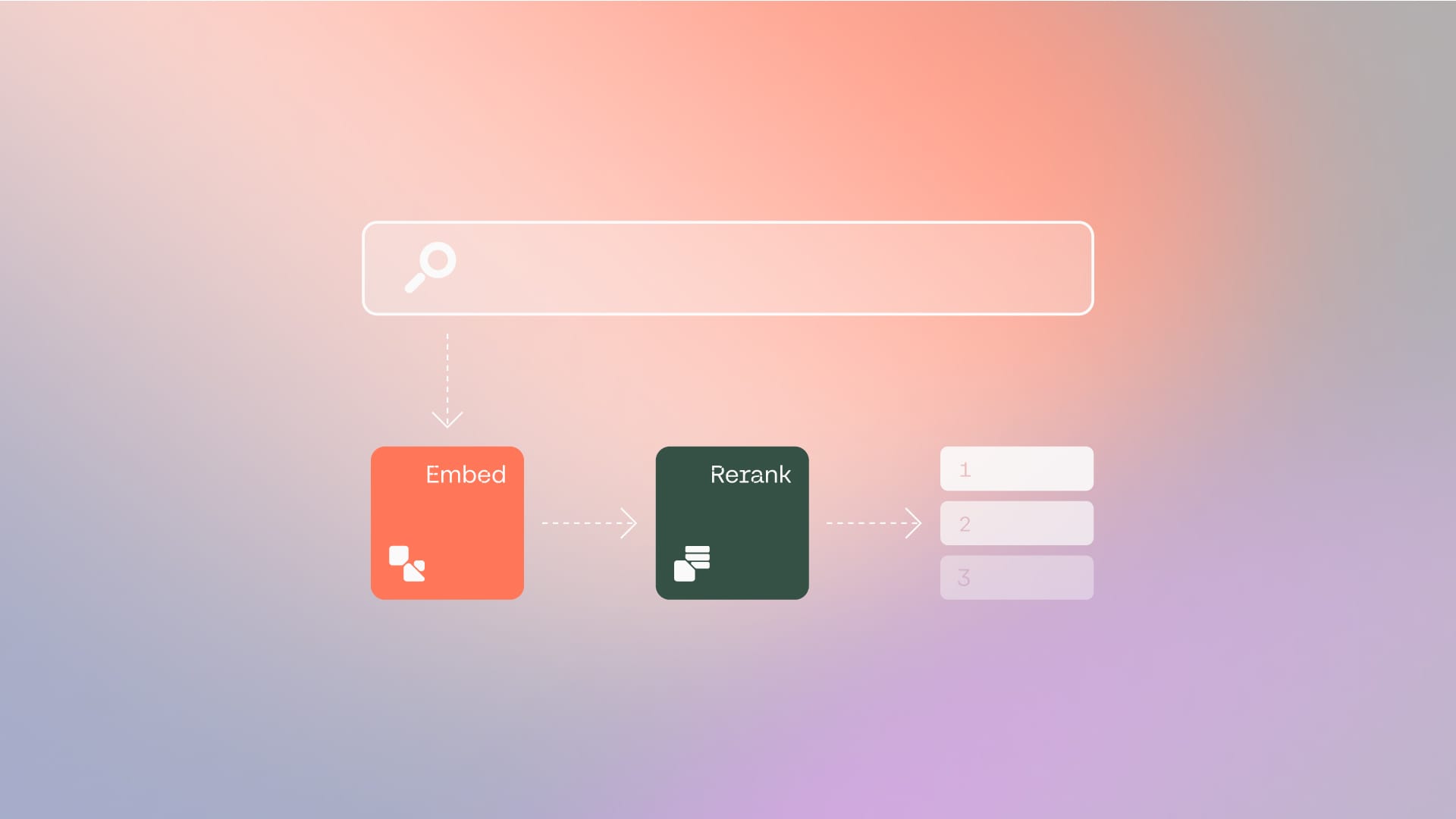
Enterprise Search and Retrieval Demystified: A Guide for RAG Users
David Stewart, Jamie LinsdellShare: