Introducing Command R+: Our new, most powerful model in the Command R family.

< Back to blog
 Meor Amer
Meor Amer
Jun 21, 2022
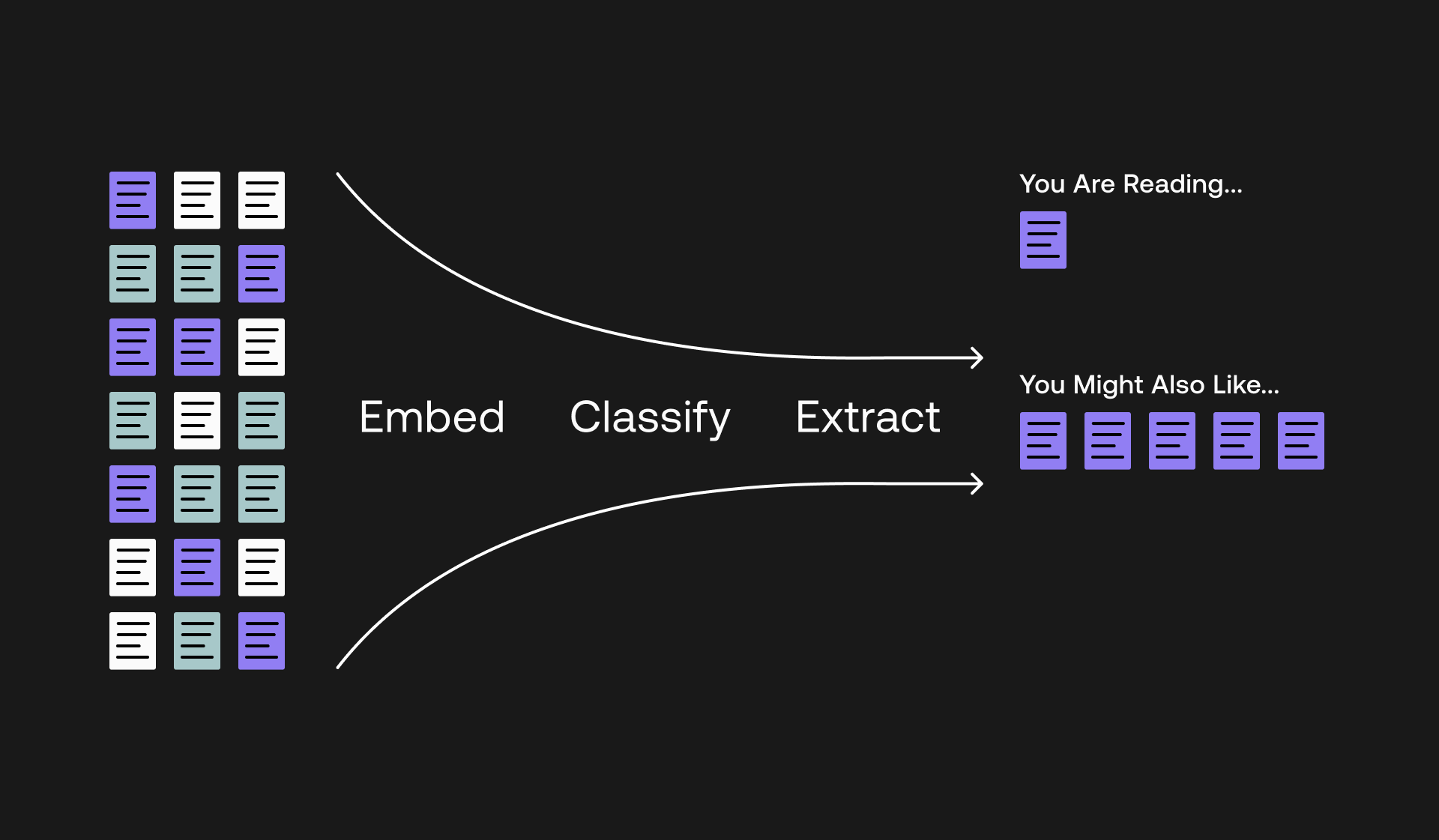
Article Recommender with Text Embedding, Classification, and Extraction
Meor AmerShare: